ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System
Abstract
Existing deep video models are limited by specific tasks, fixed input-output spaces, and poor generalization capabilities, making it difficult to deploy them in real-world scenarios. In this paper, we present our vision for multimodal and versatile video understanding and propose a prototype system, ChatVideo. Our system is built upon a tracklet-centric paradigm, which treats tracklets as the basic video elements and employs various Video Foundation Models (ViFMs) to annotate their properties e.g., appearance, motion, etc. All the detected tracklets are stored in a database and interact with the user through a database manager. We have conducted extensive case studies on different types of in-the-wild videos, which demonstrates the effectiveness of our method in answering various video-related problems.
Framework
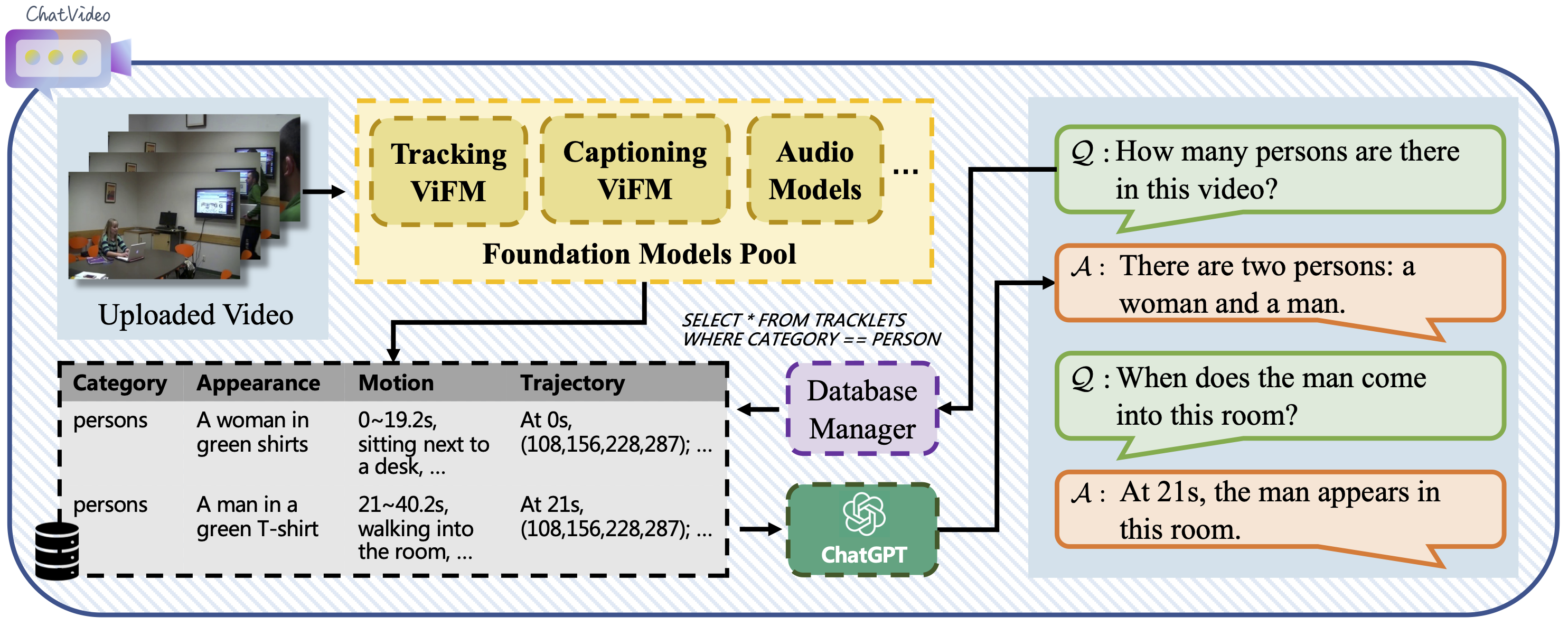
Fig.1 An overview of the proposed framework.
Demo
Case Studies
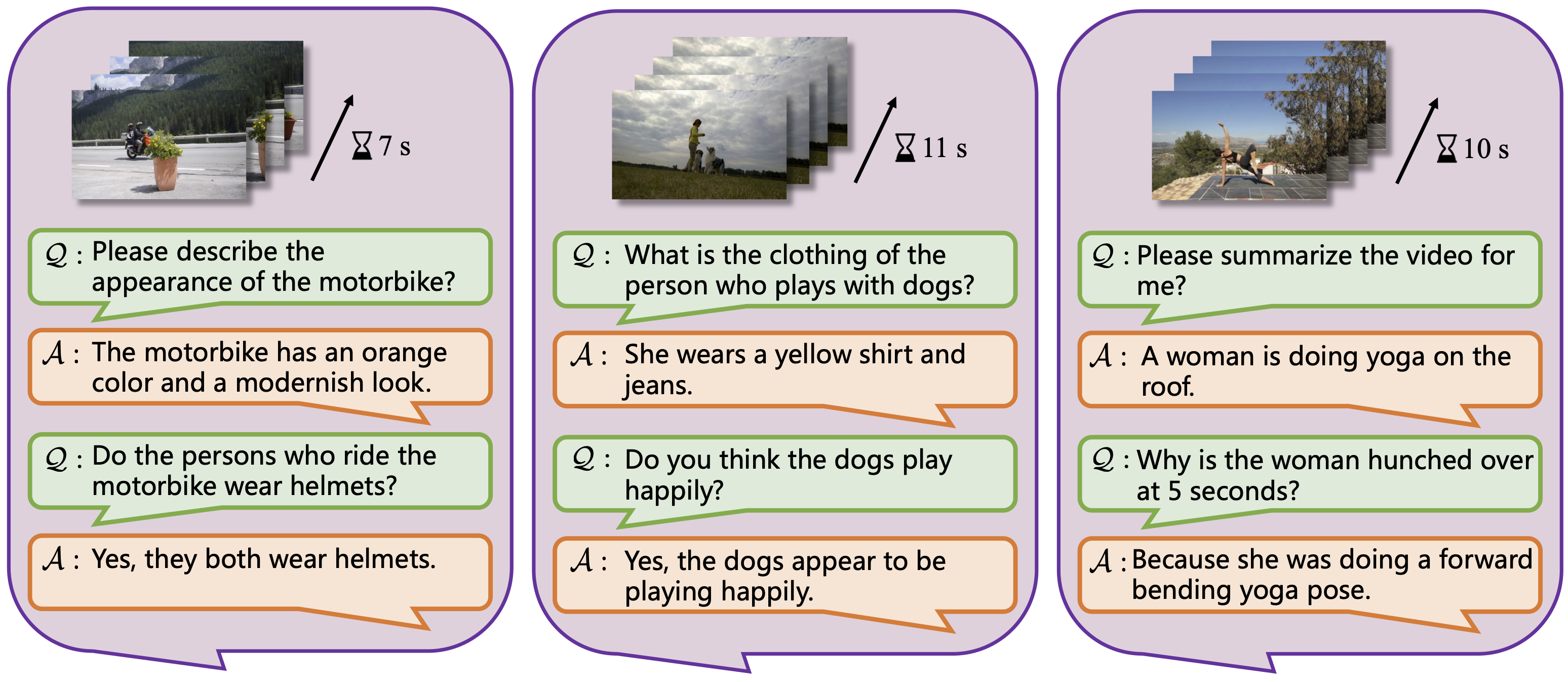
Fig.2 Appearance Understanding.
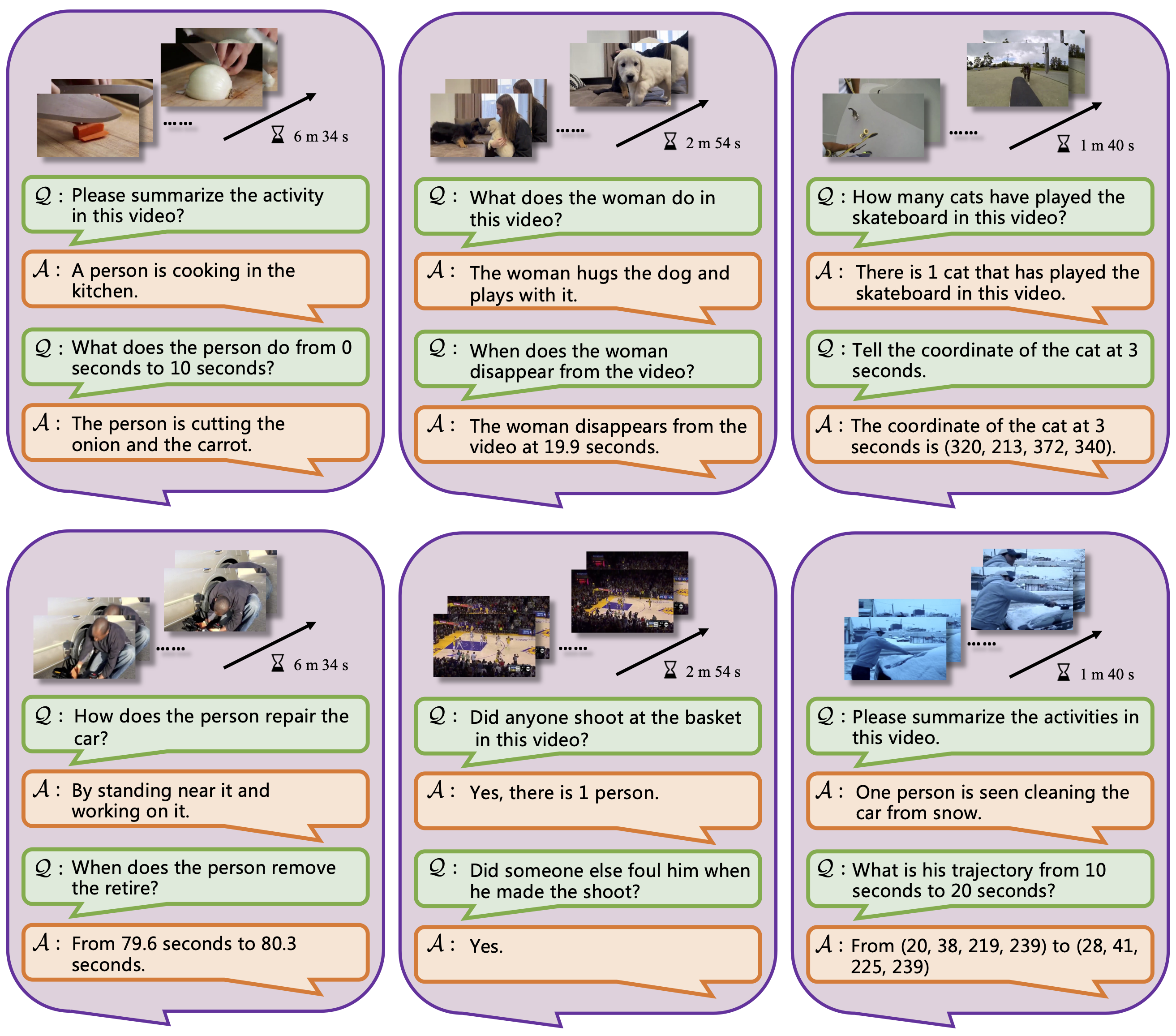
Fig.3 Motion Understanding.
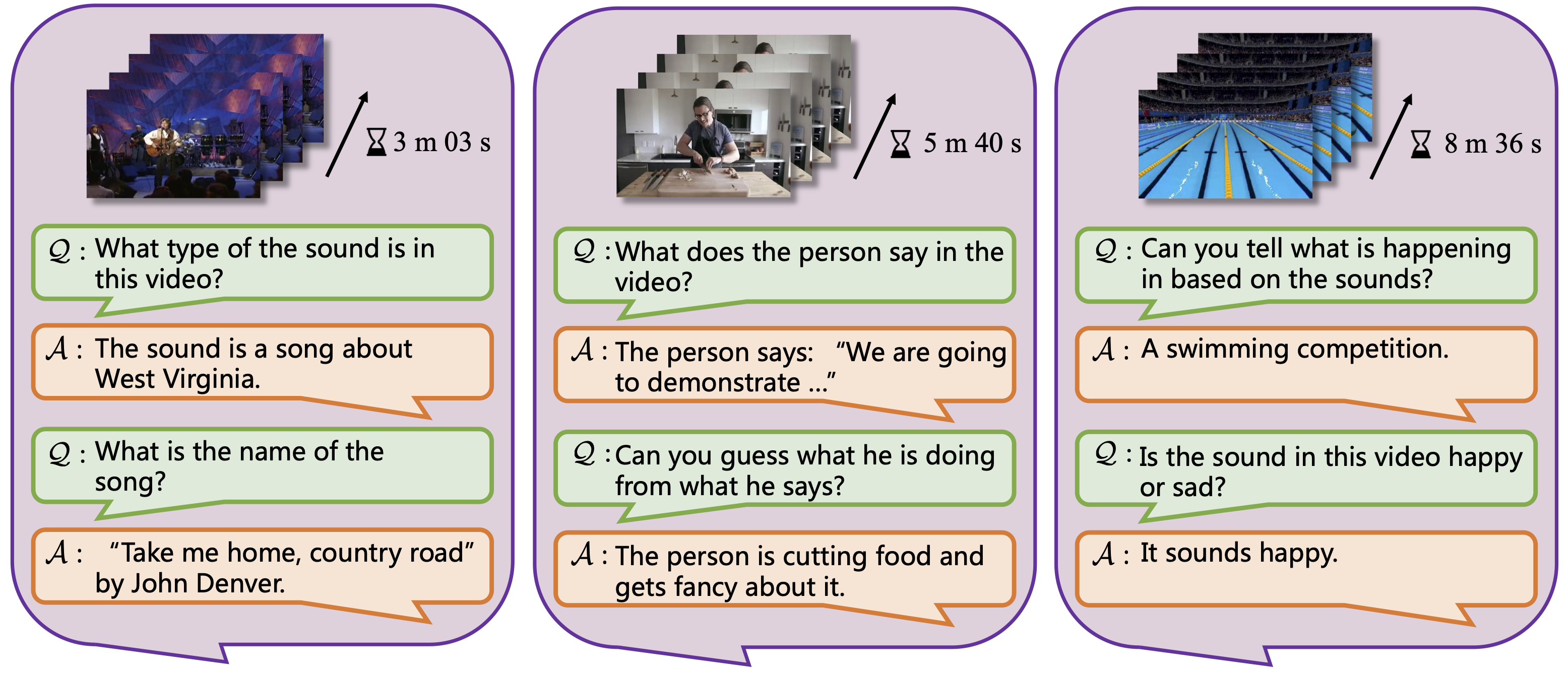
Fig.4 Audio Understanding
Citation
@article{wang2023chatvideo, title={ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System}, author={Wang, Junke and Chen, Dongdong and Luo, Chong and Dai, Xiyang and Yuan, Lu and Wu, Zuxuan and Jiang, Yu-Gang}, journal={arXiv preprint arXiv:2304.14407}, year={2023} }